AMX(Advanced Matrix Extension)是Intel推出的一种 CPU 指令集扩展技术,用于加速矩阵/向量计算。它提供专用的寄存器和指令,优化矩阵乘法、卷积等运算。
AMX的主要特点包括:
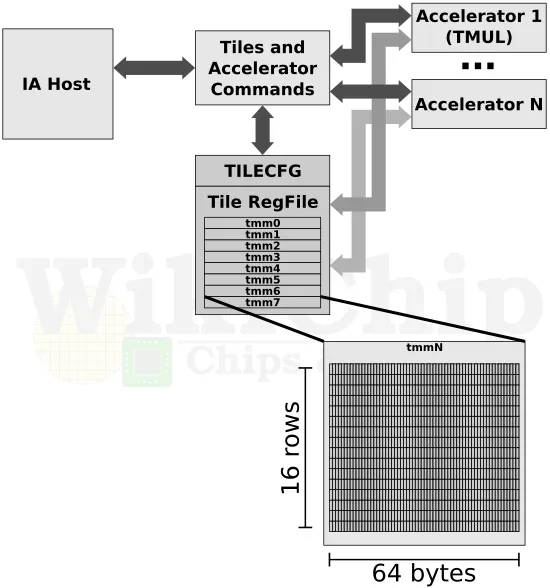
1. 专用的矩阵/向量寄存器。AMX增加了8个128比特宽的专用寄存器,用于高效存储矩阵和向量。
2. 优化的矩阵/向量指令。AMX新增近60条矩阵/向量专用指令,包括乘法、加法、复制等,专用于矩阵和向量运算。
3. 寄存器缓冲区。AMX还新增一个矩阵缓冲区,用于临时存储矩阵计算的中间结果,避免访问主存。
4. 指令级并行。AMX充分利用CPU的指令级并行性,可以同时执行多条矩阵计算指令,显著提高性能。
5. 与AVX512协同工作。AMX与Intel AVX512指令集协同工作,可以一起完成更复杂的矩阵运算。
AMX的主要应用场景在于:
1. 深度学习和神经网络。AMX可以显著加速矩阵运算密集型的神经网络训练和推理过程。
2. 线性代数运算。AMX可以加速各种矩阵乘法、向量运算,提高线性代数程序的性能。
3. 图像/视频处理。许多图像和视频处理算法依赖矩阵运算,AMX可以提升这些算法的执行速度。
4. 科学计算。许多科学计算也会大量使用矩阵运算,AMX同样适用于这些场景。
---------------------------------------------
AMX作为Intel CPU的一项重要扩展,专注于矩阵/向量计算,可以为各种依赖矩阵运算的算法和程序带来显著性能提升。随着其普及,相信会应用于更多应用场景。
[1] @halomaster • 16 Apr 2023, 02:18 GMT
Intel 先进矩阵扩展(AMX)和苹果 M1 芯片的矩阵指令单元都目的是加速矩阵运算和神经网络计算。具体来说:
Intel AMX:
- AMX 是 Intel Ice Lake 处理器中引入的新特性,提供专门的矩阵乘法和累加指令
- AMX 提供独立的矩阵寄存器存放浮点数矩阵。这些寄存器可以直接在矩阵乘法和加法指令中使用,不需要先加载到普通寄存器中。
- AMX 支持矩阵乘法和矩阵加法,以及对称矩阵乘法等操作。这可以有效加速神经网络中的全连接层和卷积层等计算。
- AMX 是 x86 指令集的扩展,任何支持 Ice Lake 的处理器都可以使用 AMX 指令,包括 CPU、GPU 以及 FPGA 等。这使得部署神经网络模型更加灵活。
苹果 M1 矩阵指令单元:
- M1 芯片具有一个专用的矩阵指令单元,提供高效的小矩阵乘法和累加功能。
- M1 矩阵指令单元提供 4 个 128 位宽的向量寄存器,每个寄存器可以看作是一个 4x4 的单精度浮点数矩阵。这些寄存器可以直接在矩阵运算指令中使用。
- M1 仅支持小矩阵(4x4)的乘法和加法。虽然覆盖的矩阵规模较小,但由于专用的矩阵运算单元,效率很高。这也适合多数神经网络层中的小矩阵计算。
- M1 矩阵指令单元是 Apple 定制的一部分,只能在 Apple 的 SoC 中使用。这限制了其部署灵活性。
--------------------------------
Intel AMX 和苹果 M1 矩阵指令单元虽然在实现上有差异,但目的都是为了加速神经网络中典型的小矩阵运算,提高计算效率。AMX 作为 x86 的扩展具有更高的部署灵活性,而 M1 矩阵指令单元则深度定制化以达到高效计算的目的。
[2] @halomaster • 16 Apr 2023, 02:24 GMT
1 of 1 pages 2 replies